Pipedrive

Scoop is able to grab your data from Pipedrive to enable sophisticated visualization and analysis.
Typical Pipedrive Use Cases with Pipedrive Only
Typical use cases for Scoop with Pipedrive data only include:
- General sales reporting with better visuals and analysis
- Weekly forecasting or pipeline views that leverage snapshotting to review changes
- Snapshotting any/all attributes on any object like Opportunities
- Analyzing sales processes to understand conversion rates and cycle times
Combining PipeDrive data with other types of data opens up very powerful analysis options that can really help a marketer optimize their performance.
Pipedrive Instant Recipes
Scoop has several instant recipes created for Pipedrive to get you started quickly. The recipes are pipeline waterfall, sales operations, sales team performance, and deal distribution.
- Pipeline waterfall: Gain powerful insights into every shift in your sales pipeline with advanced waterfall analysis. Track what’s been added, removed, won, lost, or resized across your entire pipeline, broken down by individual deal owner and deal type. Dive deeper into specific deals to take immediate action and drive results
- Sales operations: Gain powerful insights into every shift in your sales pipeline with advanced waterfall analysis. Track what’s been added, removed, won, lost, or resized across your entire pipeline, broken down by individual deal owner and deal type. Dive deeper into specific deals to take immediate action and drive results
- Sales team performance: Access real-time sales metrics like pipeline performance, deal velocity, and forecasting directly from Pipedrive. This recipe consolidates key data to offer immediate insights, helping you track trends and optimize your sales operations
- Deal distribution: Understand which types of deals are being done and who is doing them. With deal distribution analysis you can see at a glance where your business is coming from
Pipedrive Snapshotting
One of the biggest uses of Scoop for Pipedrive is snapshotting. Scoop can snapshot any object, including Pipedrive sales objects. This allows for critical analysis of fundamental sales processes by understanding how things change in a sales process and why. Even Salesforce.com has limited abilities to analyze changes and whole industries have been built around that. Scoop gives greater capabilities for Pipedrive users than anything available to Salesforce customers (except those using Scoop).
AI-Assisted Setup
When connecting Pipedrive to Scoop, choose "Guide me with AI" for an intelligent, guided setup experience.
Available Analysis Templates
| Template | Object | Data Mode | Best For | What You'll Analyze |
|---|---|---|---|---|
| Sales Pipeline (Default) | deals | Snapshot | Deal tracking & forecasting | Title, value, stage, status, owner |
| People & Contacts | persons | Sync | Contact management | Names, emails, phones, ownership |
| Organizations | organizations | Sync | Company accounts | Company info, addresses |
| Activities | activities | Sync | Engagement tracking | Activity type, subject, due dates |
Example Questions You Can Answer
Sales Pipeline:
- "What's our win rate by deal stage?"
- "How long do deals typically spend in each stage?"
- "Which reps have the highest average deal size?"
- "What's the average time in each pipeline stage?"
- "How does deal velocity vary by deal type?"
Contacts & Organizations:
- "How many new contacts were added this month?"
- "Which organizations have the most open deals?"
- "What's our contact-to-deal ratio?"
- "Which organizations have grown the most this quarter?"
- "What's the average number of contacts per organization?"
Activities:
- "How many activities per deal before closing?"
- "What types of activities are most common?"
- "Which reps are logging the most activities?"
- "What's the correlation between activity volume and win rate?"
- "How does activity mix vary by deal stage?"
Need Something Different?
If the templates above don't match your needs, select "Something else" and describe what you want to analyze. For example:
- "I want to track deals by a custom field"
- "I need to analyze activity patterns over time"
- "I want to focus on a specific pipeline"
Scoop's AI will recommend the right configuration for your specific use case.
Snapshotting for Pipeline Analysis
Configure your Deals extract as a Snapshot dataset to track deal changes over time:
- Track deal progression through pipeline stages
- Measure stage conversion rates
- Identify deals that are slipping
- Compare pipeline snapshots week-over-week
Pro Tip: Enable snapshotting on day one. Sales ops teams typically need 30-90 days of snapshot history for meaningful cycle time and conversion analysis.
Connecting to Pipedrive
To connect to Pipedrive as a datasource, create a new dataset linked to Pipedrive. First, on the datasets page, select applications as a source:
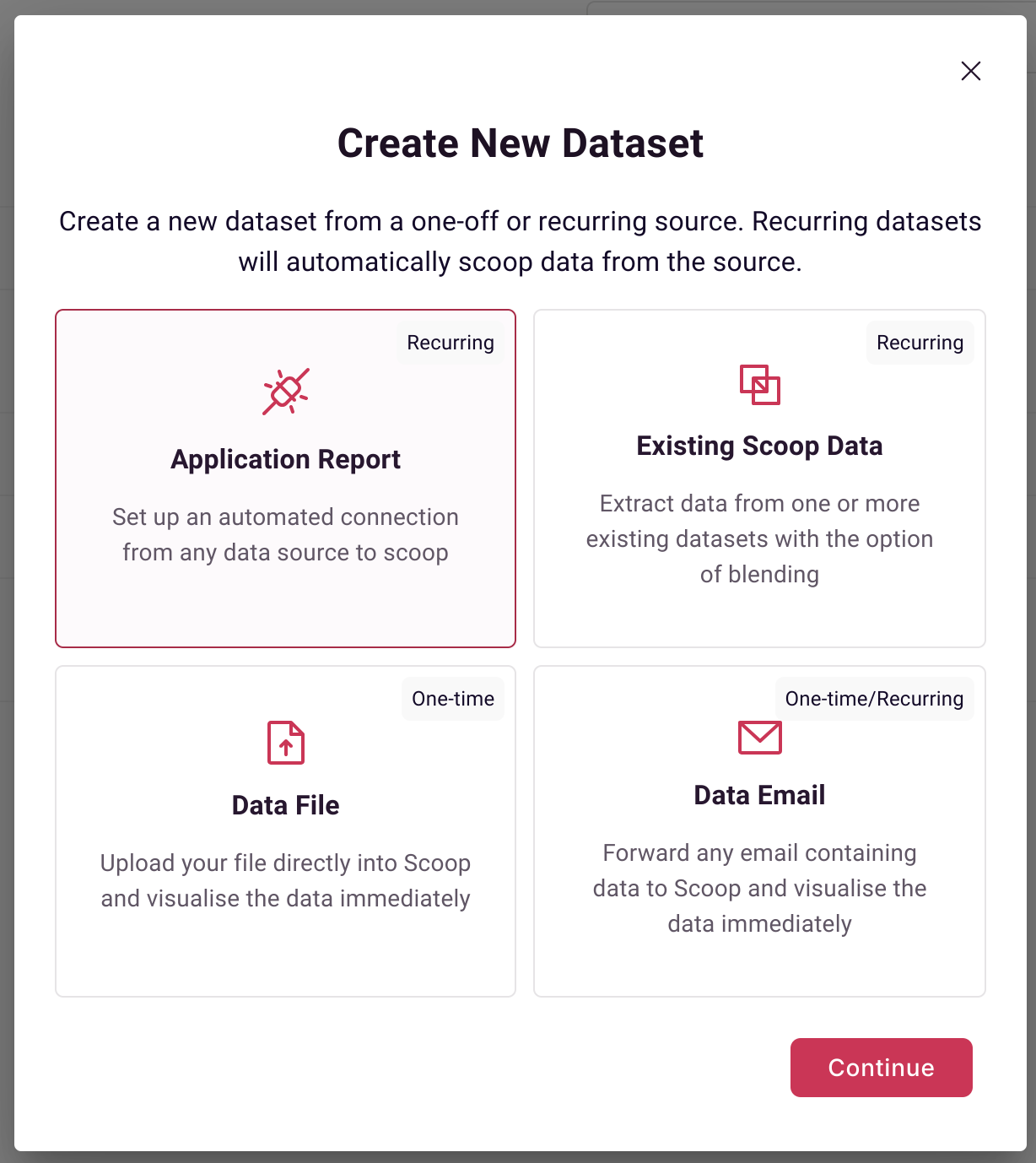
Next, select Pipedrive:
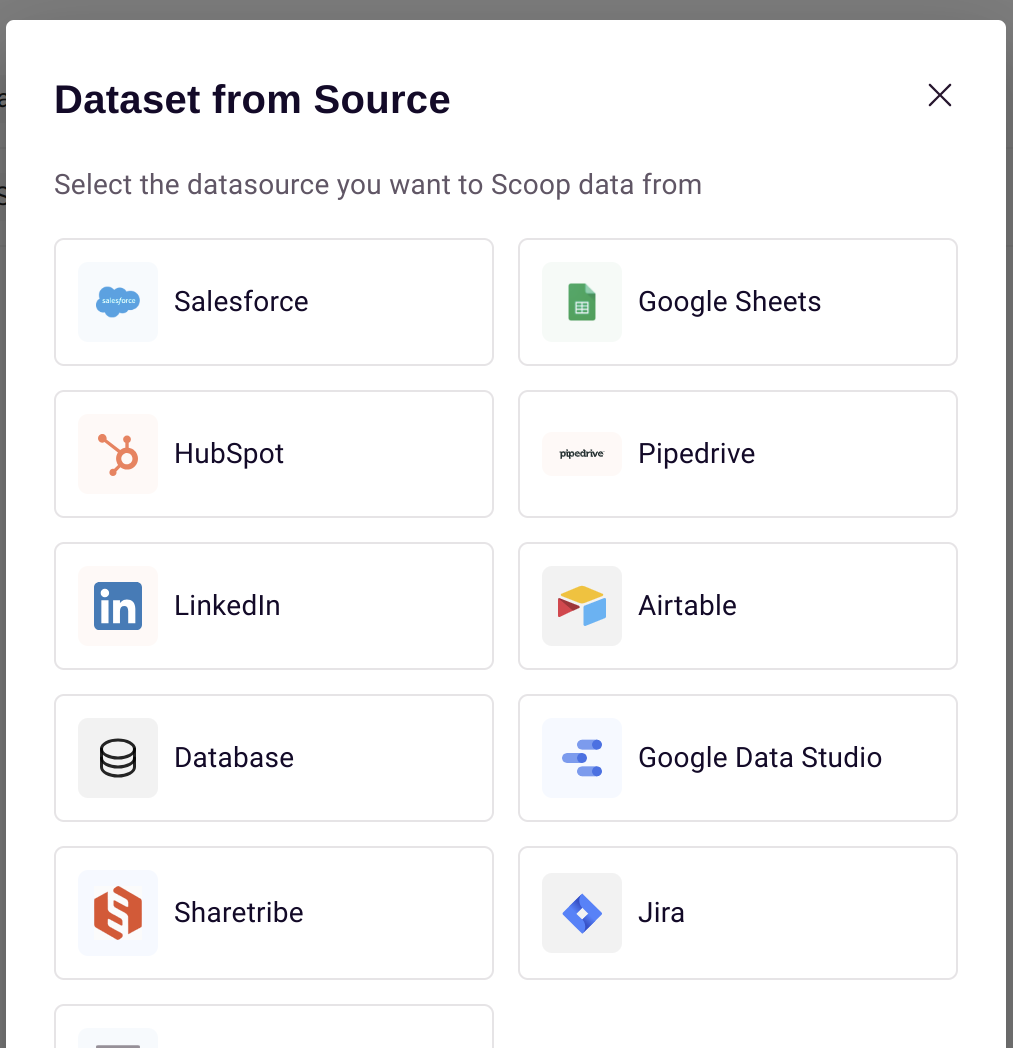
Loading from a Report vs. API
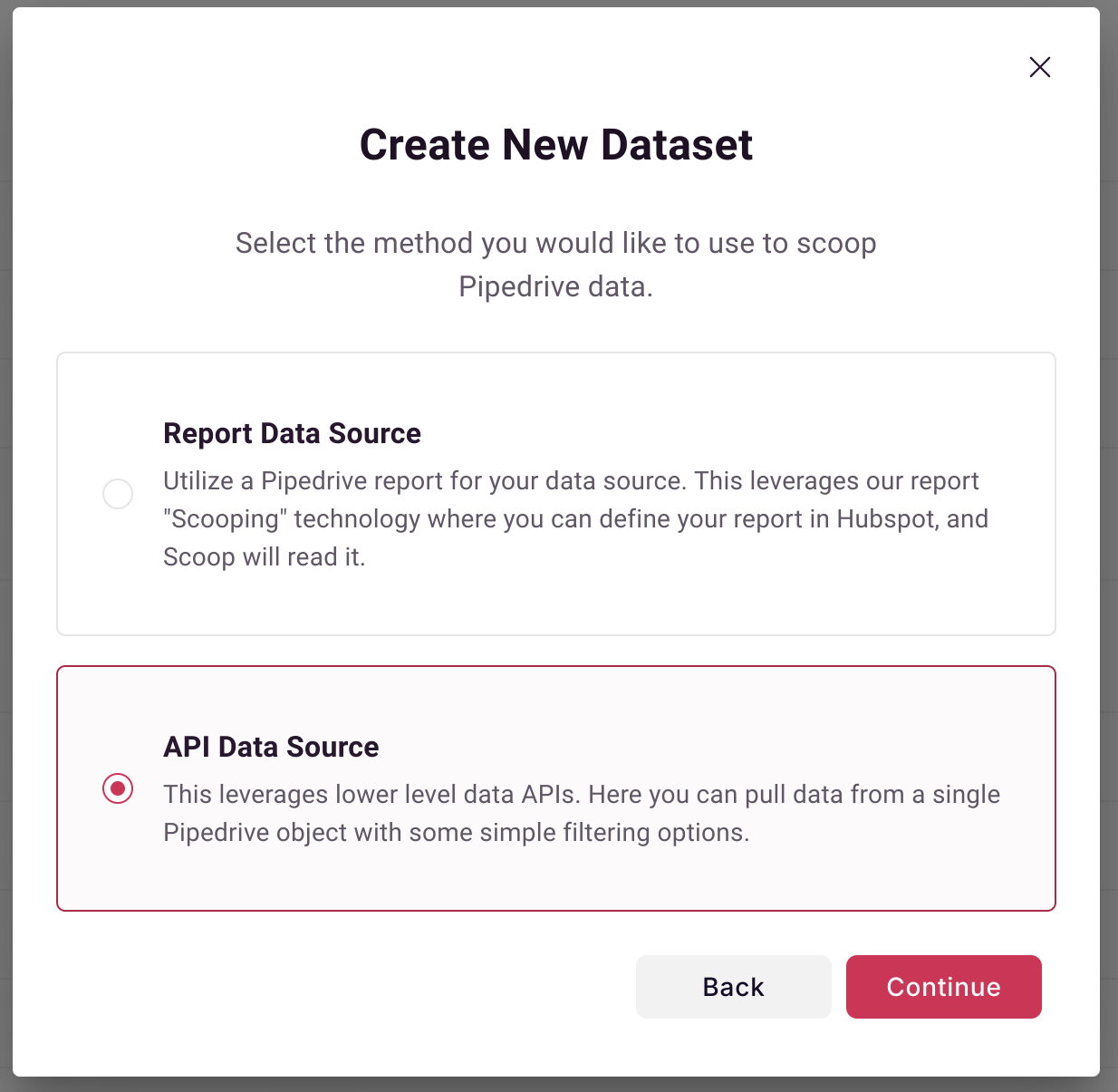
With Pipedrive you can select either a report data source or using the API as a data source. The advantage of using a report as a data source is that any linked fields from different objects will be properly displayed in your report and can therefore be easily loaded. With the API, often items that link to different objects do so via an ID field. This requires you to bring in both objects and then use Scoops blending capabilities to lookup the required field from the linked object.
Loading from the API
Select API Data Source:
Select whether you are selecting an object that you want to snapshot daily, or an object which is transactional (e.g. an activities object).
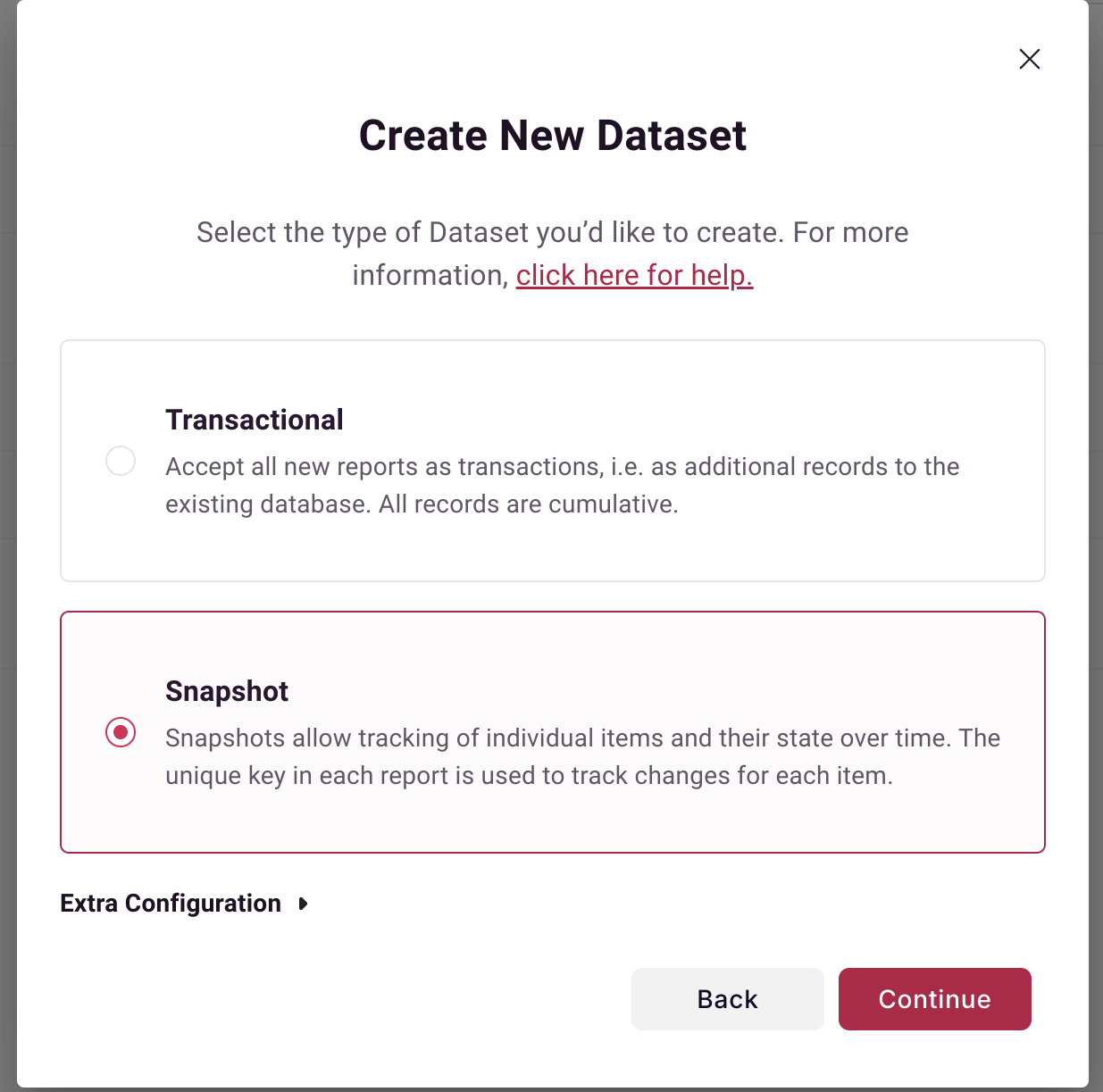
After connecting to Pipedrive to Scoop, select the object that you wish to extract, and the columns that you wish to extract.
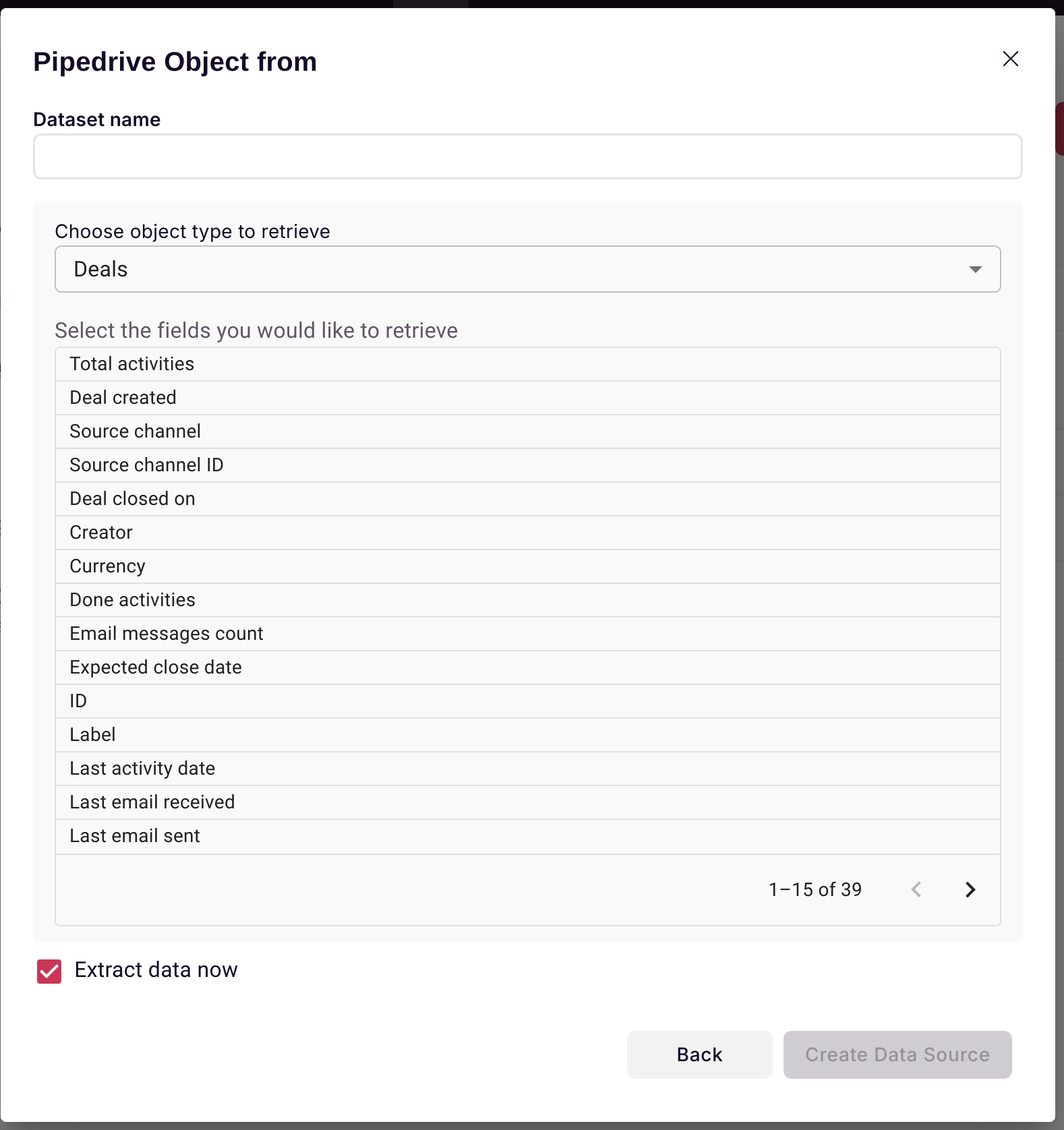
Also, select a dataset name. After you save this dialog, you can elect to have Scoop run an immediate extract (by checking the extract data now button). Scoop will automatically run this extract overnight each day after you set this up.
Writing back to Pipedrive from a Scoop dataset
With Scoop you can blend data with other datasets and create new fields with ease. Scoop's ability to use spreadsheet logic gives you that same spreadsheet flexibility to add arbitrary and powerful calculations to your dataset. It is often useful to then bring those sophisticated calculations back into your source application. Scoop's API Writeback feature allows you to take any Scoop dataset and write values back into your Pipedrive application. This means that you can extract data from Pipedrive (which is necessary to extract the Pipedrive record ID which is required to write back into Pipedrive), blend it with other data or create new calculations and then push those back into your Pipedrive application.
In order to write back into Pipedrive, you must first establish an API connection to Pipedrive and extract records that you wish to augment (see above). The Record ID will be part of your extracted dataset. You can either create calculated columns with that dataset, or you can blend that dataset with others in Scoop to create a new dataset. Be sure to make sure that the Record ID stays with your records as you blend them together (i.e. always select that column when building a new blended dataset).
Once that is done, you can now update Pipedrive whenever your dataset in question is processed. When that connection is established, the following option becomes available on the dataset menu:
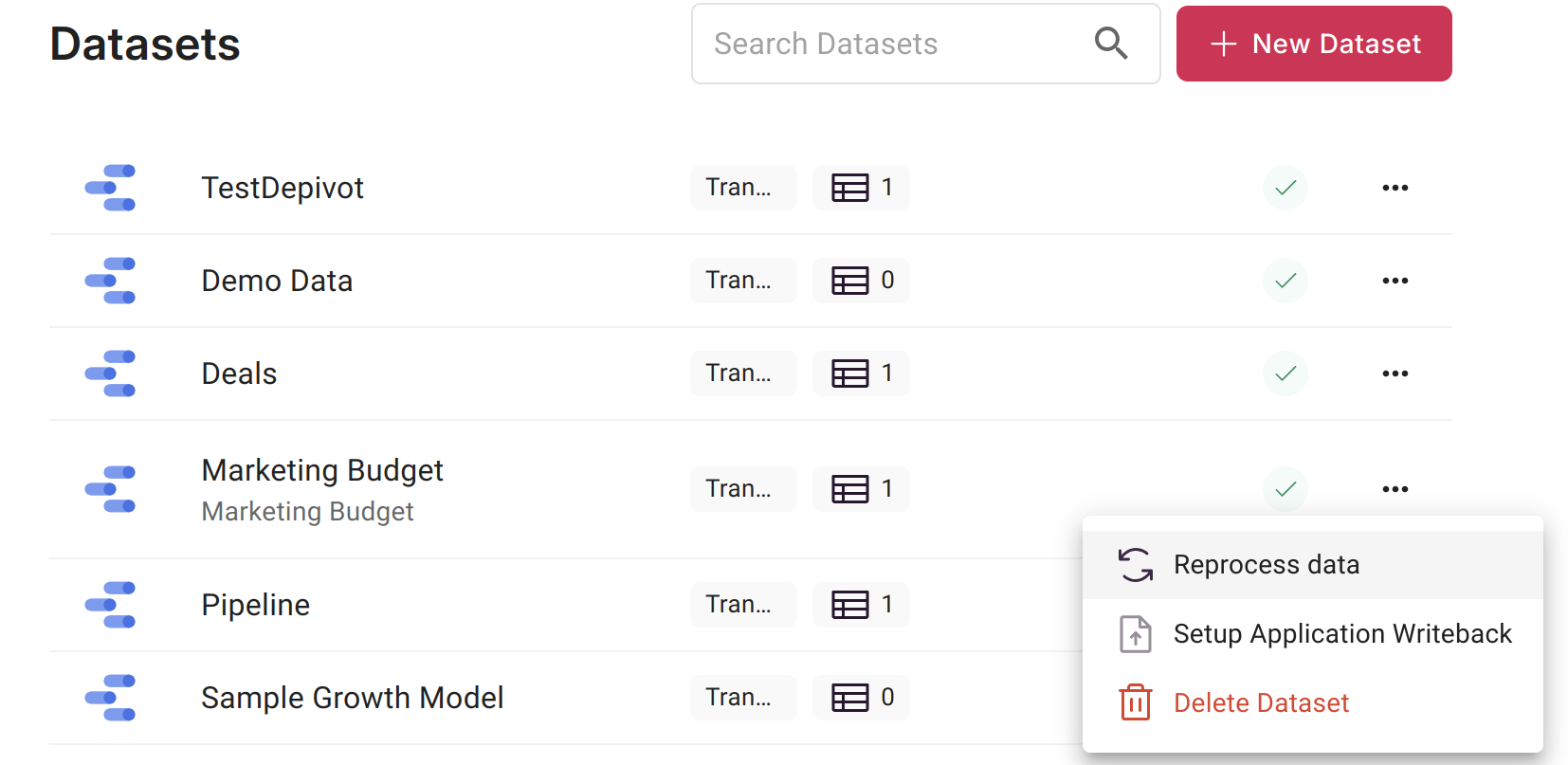
You can select "Setup Application Writeback" to create a writeback definition for Scoop. This definition tells Scoop what to do each time that dataset is processed. When processing is done, it will use that dataset and take the fields that you map and write them back to Pipedrive using the Record IDs that you initially extracted.
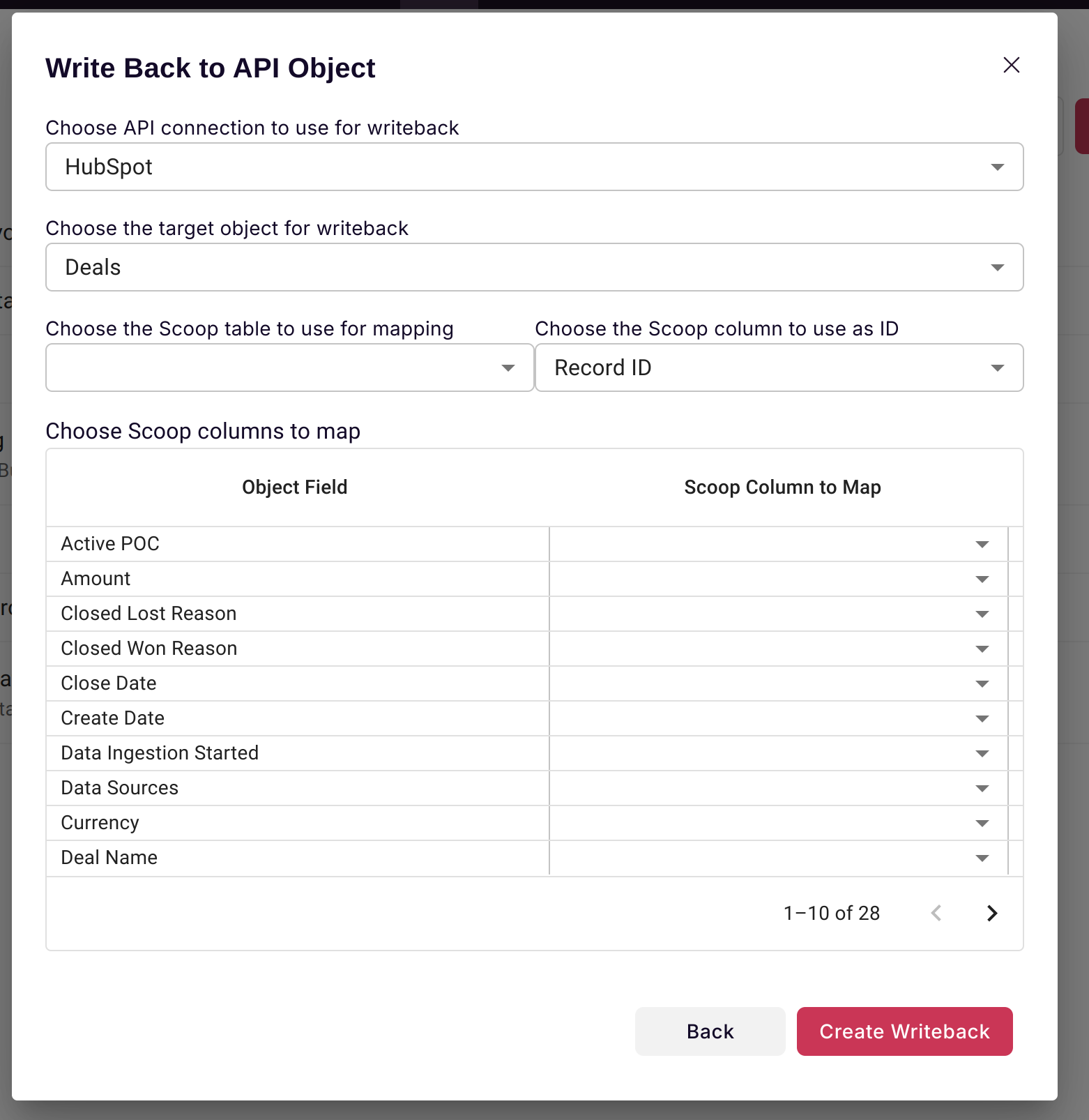
The definition essentially allows you to pick fields from one table within your dataset and map those back to fields within Pipedrive.
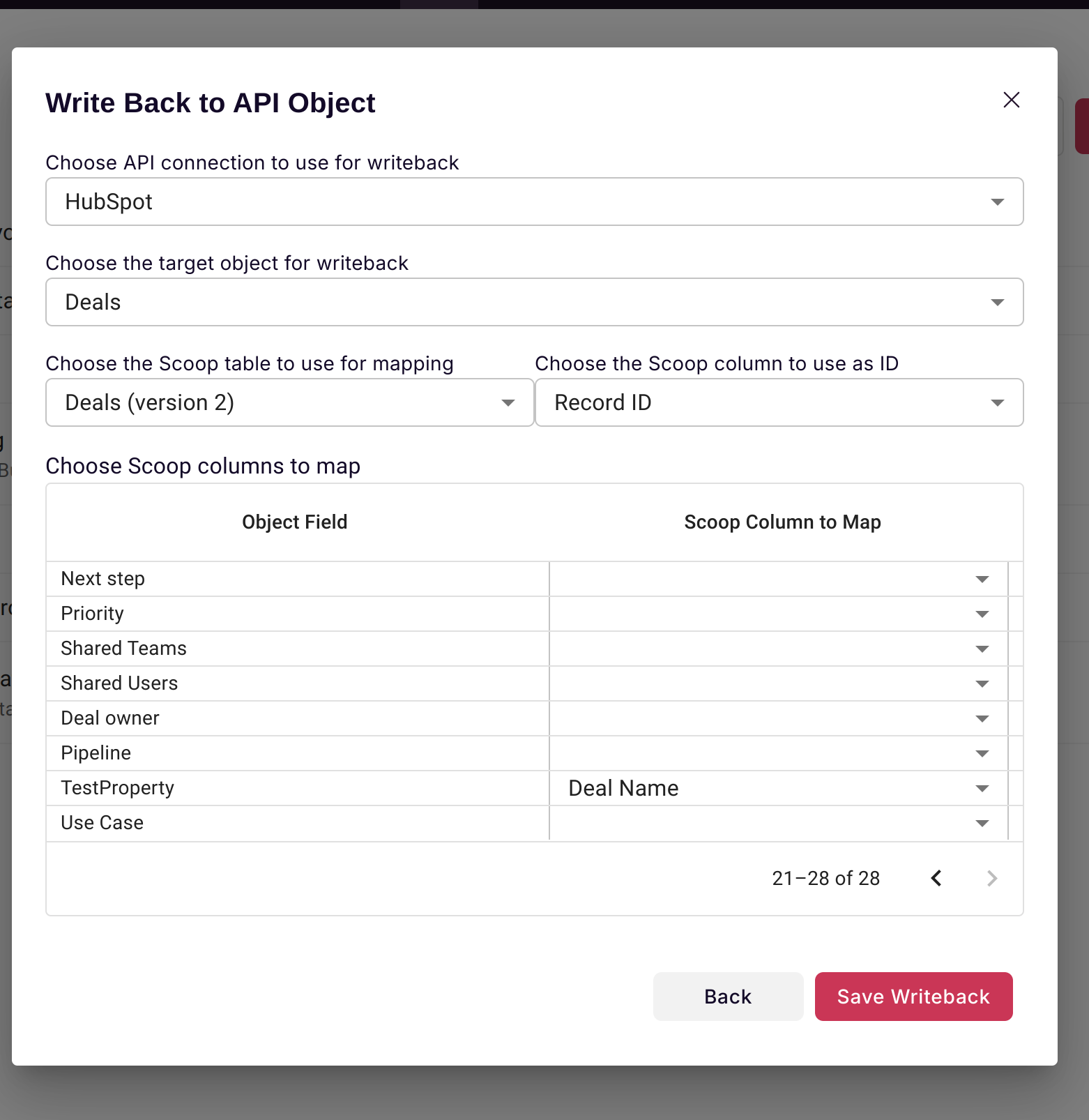
So if, for example, you wanted to map a single column in Pipedrive to a Scoop dataset, you simply select from the dropdown which Scoop dataset column you want to use. Once that is done, each time that dataset is processed, Scoop will update Pipedrive to ensure that that field will contain the value calculated in Scoop.
Updated 6 months ago