Handling Report Changes
How Scoop adapts when your source reports change structure
Source reports change over time. Fields get added, columns get renamed, and report structures evolve. Scoop intelligently handles these changes, automatically adapting your datasets without breaking existing analyses or requiring manual intervention.
How Scoop Handles Report Changes
When you load a new report, Scoop performs intelligent matching:
New Report Arrives
↓
┌─────────────────────────────┐
│ 1. Analyze column structure │
│ 2. Detect unique key │
│ 3. Compare to existing data │
└─────────────────────────────┘
↓
┌───┴───┐
│Match? │
└───┬───┘
↓ ↓
Yes No
↓ ↓
Add to Create new
existing table or
table adjust schemaThe Matching Process
Step 1: Identify Columns
Scoop examines the incoming report to identify:
- Column names and positions
- Data types (text, number, date)
- Which columns contain unique values
Step 2: Detect Unique Key
A unique key is a column that:
- Uniquely identifies each row (like Opportunity ID)
- Appears exactly once per record
- Remains consistent across report versions
When Scoop finds a unique key, it can confidently match records across schema changes.
Step 3: Match to Existing Tables
| Scenario | Action |
|---|---|
| Columns match exactly | Add data to existing table |
| New columns added, unique key matches | Alter table to add columns |
| New numeric columns, no unique key | Alter table to add columns |
| Different structure, no key match | Create new table |
Types of Changes Scoop Handles
Adding New Columns
Most common scenario — You add a field to your source report.
Before: [ID, Name, Amount, Stage]
After: [ID, Name, Amount, Stage, Region, Owner]What happens: Scoop adds the new columns to the existing table. Historical data will have NULL values for the new columns; new data will have values.
Removing Columns
Scenario: You remove a field you no longer need.
Before: [ID, Name, Amount, Stage, OldField]
After: [ID, Name, Amount, Stage]What happens: The column remains in the table (for historical data) but new records won't have values for it.
Renaming Columns
Scenario: Column header name changes.
Before: [ID, Customer_Name, Amount]
After: [ID, CustomerName, Amount]What happens: Scoop treats the renamed column as a new column and the old column as removed. To preserve continuity, consider using Calculated Columns to map the old name to the new name.
Reordering Columns
Scenario: Columns appear in a different order.
What happens: Scoop matches by column name, not position. Column order changes don't affect matching.
When Matching Fails
Sometimes Scoop creates a new table instead of adding to an existing one. This happens when the schema difference is significant enough that automatic adaptation isn't safe.
Why a New Table Gets Created
| Reason | Example |
|---|---|
| No unique key to anchor matching | Report lacks ID column |
| Completely different column set | Wrong report uploaded |
| Aggregation level changed | Detail vs. summary report |
| Different text columns | Different groupings possible |
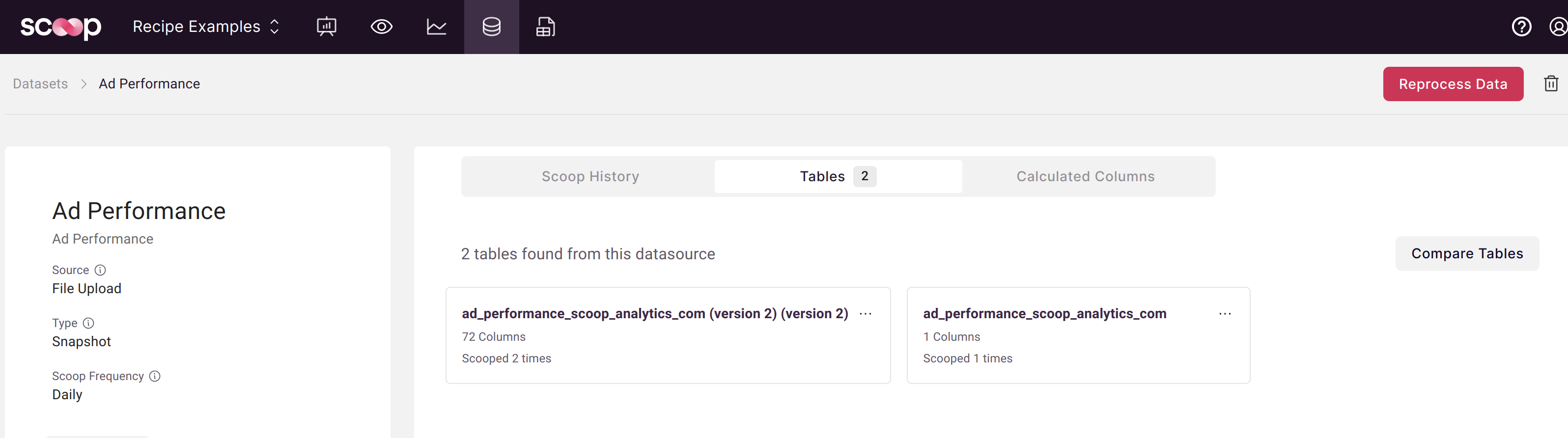
Comparing Tables
When you see multiple tables in your dataset, use the Compare Tables feature:
- Open your dataset
- Click the Tables tab
- Click Compare Tables
The comparison view shows both table schemas side-by-side:
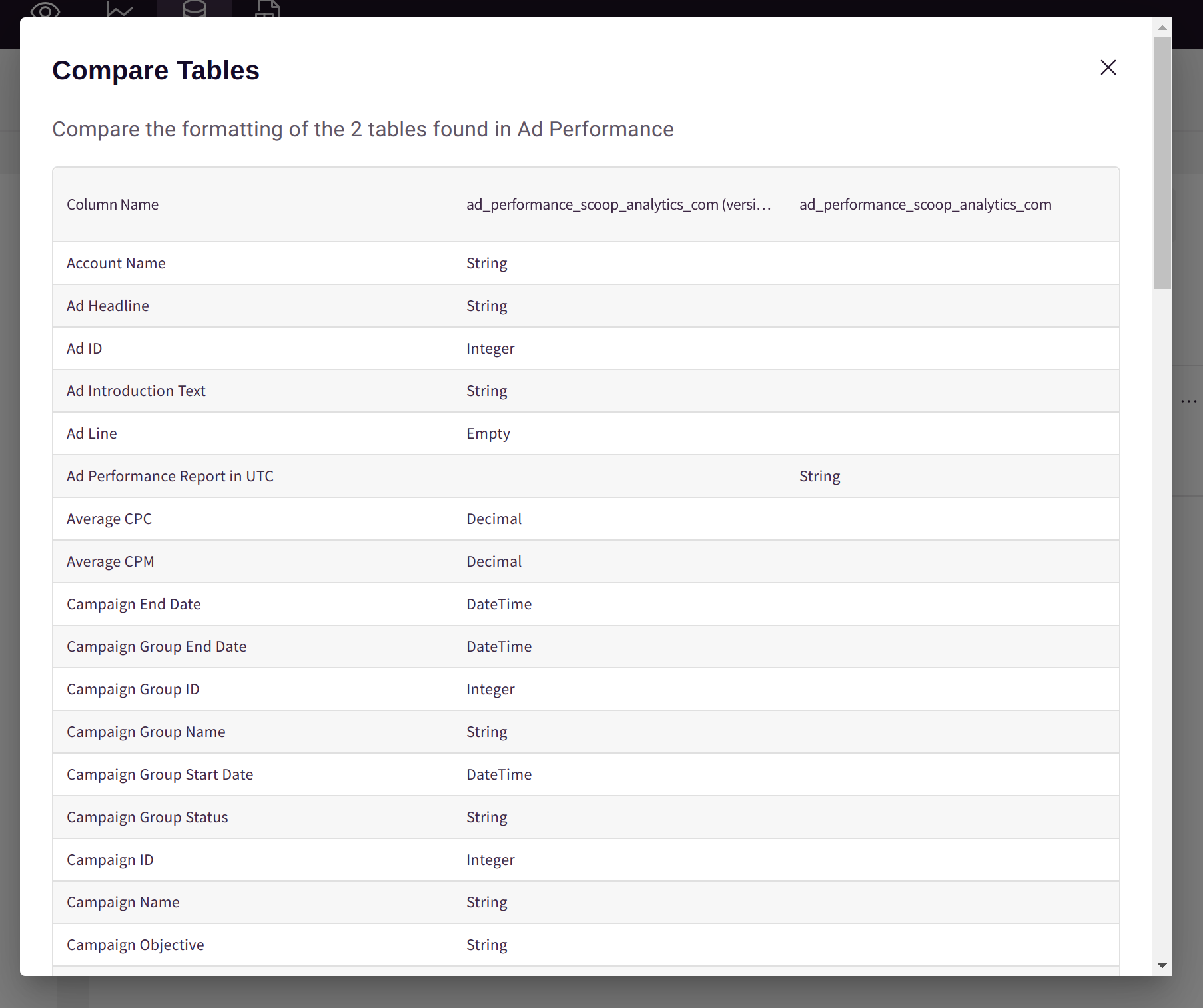
Look for:
- Missing columns — Removed in one version
- Extra columns — Added in one version
- Type differences — Column changed from text to number
- Name variations — Similar names with different spelling
Merging Tables
If two tables should be one dataset:
- Identify which table has the correct structure
- Delete the incorrect report loads (see below)
- Reload reports with consistent structure
- Reprocess the dataset
Deleting Bad Reports
Occasionally a malformed report gets loaded. You can remove it without affecting other data.
How to Delete a Report
- Open the dataset
- Go to Scoop History tab
- Find the problematic report load
- Click the trash can icon
- Confirm deletion
- Reprocess the dataset
The deleted report is removed from Scoop's history. When you reprocess, that data won't be included.
When to Delete Reports
| Scenario | Action |
|---|---|
| Wrong file uploaded | Delete and upload correct file |
| Corrupt or incomplete data | Delete and reload |
| Test data accidentally loaded | Delete test loads |
| Duplicate loads | Delete duplicates |
What Gets Deleted
- The specific report load entry
- Data from that load in the processed dataset (after reprocessing)
- NOT: Other report loads, calculated columns, or analyses
Best Practices
Preparing for Schema Changes
Before making changes to source reports:
- Document the change — Know what's being added/removed
- Consider timing — Make changes at the start of a period if possible
- Verify unique keys — Ensure ID columns remain consistent
- Test first — Load a sample before full production load
Maintaining Report Consistency
| Practice | Benefit |
|---|---|
| Keep unique ID columns | Enables confident matching |
| Use consistent naming | Prevents split tables |
| Avoid mid-period changes | Cleaner historical analysis |
| Document report versions | Easier troubleshooting |
Handling Major Changes
For significant report restructuring:
- Create a new dataset — Don't force incompatible schemas together
- Blend with history — Use Blending to combine old and new
- Map columns — Use calculated columns to align naming
- Archive old dataset — Keep for historical reference
Troubleshooting
Multiple Tables Appearing
Symptom: Dataset shows 2+ tables when you expected one.
Diagnosis:
- Compare tables to identify differences
- Check for schema changes in source
- Verify unique key consistency
Resolution:
- Delete incorrect loads and reprocess, OR
- Create new dataset with consistent schema
Columns Not Appearing
Symptom: Added a column to source, but it's not in Scoop.
Diagnosis:
- Check if new load went to a different table
- Verify column name matches expectations
- Confirm report was actually reloaded
Resolution:
- Ensure new report loads match existing table structure
- Reprocess dataset to see new columns
Historical Data Issues
Symptom: Old data missing after schema change.
Diagnosis: New table may have been created for new schema.
Resolution:
- Use Compare Tables to understand the split
- Consider blending tables if they should be together
- Accept split if schemas are truly incompatible
Related Topics
- Snapshot Datasets - Tracking changes over time
- Blending Datasets - Combine multiple sources
- Adding Calculated Columns - Map column names
- Reprocessing Data - Rebuild dataset from history
Updated 7 months ago